All PORI Repositories¶
The platform has two main components: a graph knowledge base (GraphKB), and a reporting application (IPR). However these are modularized across several repositories listed below.
An overview of each project is given below. The projects are grouped by their type of development expertise.
Front-End Web Development¶
In general our web clients are written in javascript/typescript and use React, Material-UI, and webpack.
There are two main web client projects as part of PORI
-
GraphKB client¶
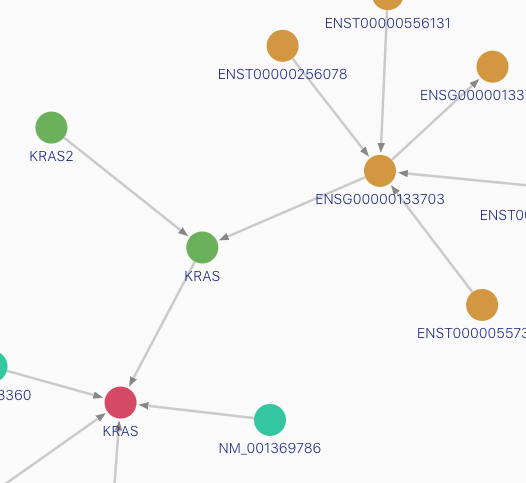
The GraphKB client is the front-end web client for the GraphKB project. The client is used to explore and manage content within GraphKB. This is the primary way for knowledge base users to interact with GraphKB. It contains a graph-based view and support for common query operations. It also allows export of results up to 5K rows (larger exports should be done via the API).
-
IPR client¶
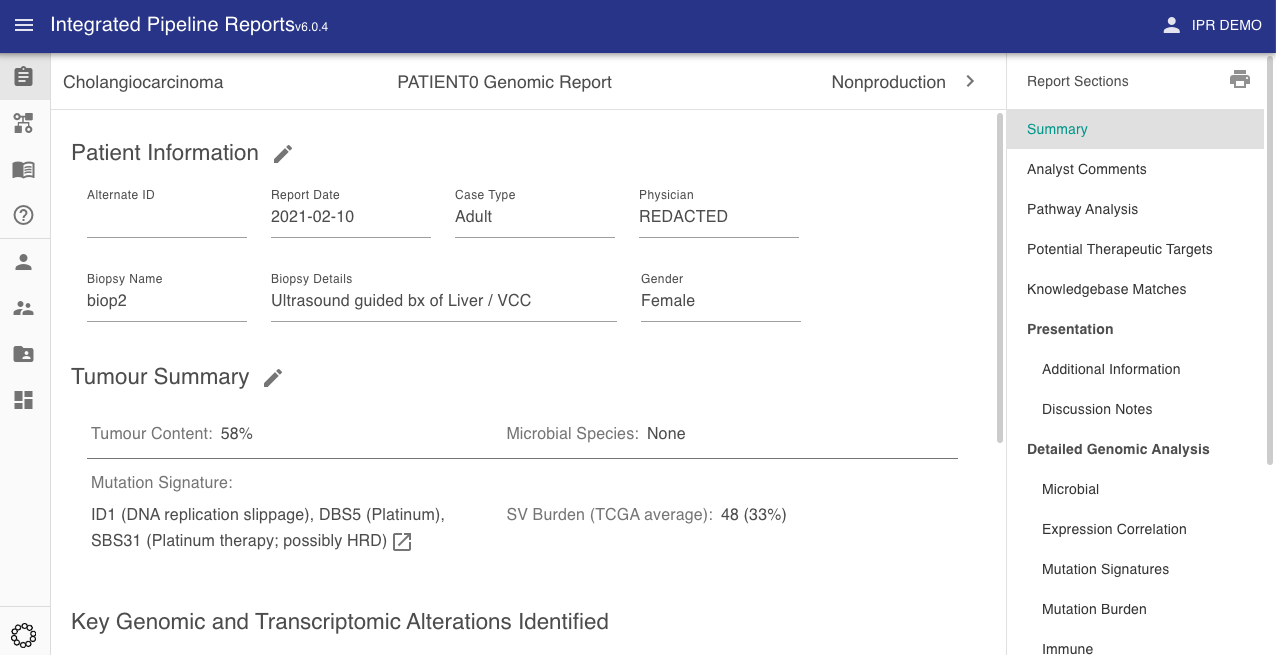
The IPR client is the front-end web application which consumes data from the IPR API. The primary function is the production and management of genomic reports. Case Analysts use the IPR client to curate and review reports prior to presentation to a molecular tumour board or dissemination.
Back-End Web Development¶
The REST APIs that are part of PORI are written in javascript and are run using NodeJS. Both are built on the popular Express framework. The database and corresponding object relational mapper (ORM) is where they differ. The IPR API uses Postgres and sequelize whereas the GraphKB API uses OrientDB and orientjs.
Both APIs implement swagger/openapi documentation for developers using the APIs.
-
GraphKB API¶

GraphKB REST API and Graph Database. The GraphKB database is a graph database which is used to store variants, ontologies, and the relevance of these terms and variants. The KB uses strict controlled vocabulary to provide a parseable and machine-readable interface for other applications to build on.
-
IPR API¶

The Integrated Pipeline Reports (IPR) REST API manages data access to the IPR database. The API is responsible for storing and serving all data for reports.
ETL / Data Loading¶
The GraphKB project also includes a loaders package which is used to import content from external knowledge bases and ontologies into GraphKB. Writing these loaders requires a strong understanding of the knowledge graph structure of GraphKB as well as the structure of the target resource. The loaders are written in javscript to be able to leverage the parser and schema JS packages used by the API and client. They are run with NodeJS. A list of the popular supported inputs can be found in the loading data section.
-
GraphKB Data Loaders¶
GraphKB loaders is responsible for all data import into GraphKB. Automatic Import modules are provided for a variety of external ontologies and knowledge bases such as: Ensembl, Entrez Genes, RefSeq, HGNC, Disease Ontology, NCI Thesaurus, CIViC, DoCM, etc.
Python Adapters¶
The popularity of python in bioinformatics makes it one of the top choices for adapters. These adapters are written to help users integrate PORI into their existing bioinformatic workflows. They are published and installed via pip.
pip install graphkb ipr
A developer reference for these packages including the function signatures and package details can be found in the developer reference section here.
-
GraphKB Python Adapter¶
Python adapter package for querying the GraphKB API. See the related user manual for instructions on incorporating this into custom scripts.
-
IPR Python Adapter¶

Python adapter for generating reports uploaded to the IPR API. This python tool takes in variant inputs as tab-delimited files and annotates them using GraphKB. The resulting output is uploaded to IPR as a report. Additional report content such as images and metadata can be passed to be included in the report upload.
-
PORI cBioportal¶

This python adapter is intended to demonstrate creating a PORI report using data exported from a cBioportal instance. It uses the expression, copy number, fusion, and small mutation data as well as available metadata to complete the reports.
Other Supporting Packages¶
There are a number of packages that are split into separate projects so that they can be re-used across the other PORI projects. For example, the GraphKB parser is used by the GraphKB API, the GraphKB Client, and the GraphKB data loaders.
-
GraphKB Parser¶
A package for parsing and recreating HGVS-like variant notation used in GraphKB. This is used by both the API and client applications. Try it out online with RunKit
-
GraphKB Schema¶

The GraphKB Schema package defines the vertex and edge classes in the DB. It is used as a dependency of both the API and client applications.